Решение задачи сегментации объекта через композицию моделей классификации и выделения главного объекта на изображении
В своей магистерской работе о распознавании калорийности блюд, были решены несколько вызовов с точки зрения механизмов работы компьютерного зрения. Рассмотрим наиболее технологически привлекательный пример получения/построения модели сегментации объекта, как совокупности классификации изображения и выделения на нем главного объекта.
Чтобы ответить на вопрос “сколько калорий находится у меня на тарелке?” понадобится предельно точно выделить еду на тарелке (сегментировать целевой объект), и определить что это (выделить класс из модели классификации).
Для данной задачи, безусловно, подойдет модель сегментации продуктов питания и готовых блюд. Единственная незадача заключается в том, что готового набора данных или нейросетевой модели решающую данную задачу для обширного числа продуктов питания и готовых блюд в открытом доступе, попросту нет. Отсутствие сбалансированных и обширных наборов данных для специфических, кастомных областей распознавания не редкость. Наборы данных для сегментации, по праву, считаются самыми трудоемкими для составления. Так как каждое изображение в таком наборе данных должно иметь метку класса и точную пиксельную маску, тогда как в классификации достаточно лишь класса объекта изображенного на изображении, а для детекции bounding-box-a с соответствующим классом. Подробнее об описанных определения основных задач компьютерного зрения, можно познакомиться на рисунке:


 |
| Пример выделения главного объекта на фотографии: источник |
Выделение главного объекта - это задача, основанная на механизме визуального внимания, в которой алгоритмы направлены на изучение объектов или областей выделяя степени внимания по всему изображению. С помощью данной модели, используя композицию результатов классификации изображения и выделение главного объекта, демонстрируется приемлимая точность в совокупном обнаружении маски объекта и его сущности. Иллюстрация механизма композиции в сравнении с сегментацией изображения:
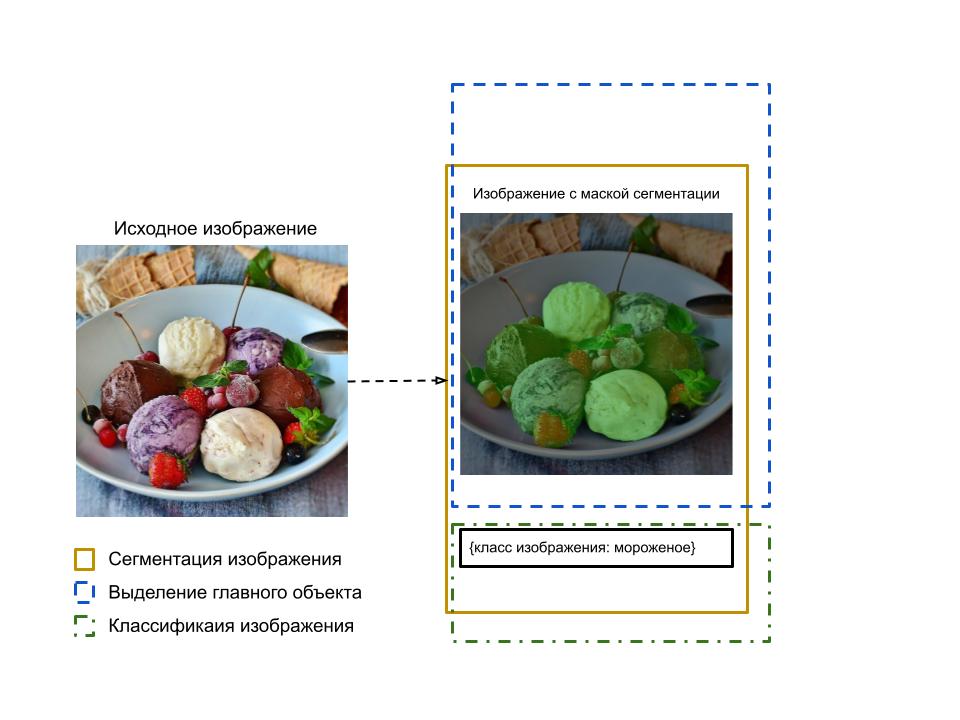
В соответствии с выводом моделей описанном на рисунке, связка обнаружения главного объекта с классификацией изображения по маске позволяет автоматизировать процесс разметки данных и делает возможным обучение модели сегментации для обширного кластера объектов. Также композиция этих моделей выполняет аналогичные функции нейросетевой модели сегментации. Возможность использования двух более "простых" в обучении и применении нейросетевых моделей вместо одной "тяжеловесной", открывает широкий простор для применения сегментации и составлении наборов данных для широкого спектра объектов нашей жизни.
Список научных статей и референсов для повторения данного эксперимента:
Научные статьи и нейросетевые модели, используемые для получения результата:
- Salient Object Detection model: u2net
- Food classification datasets: food-101
- Classification pretrained models: pytorch classification hub
Ссылка на репозиторий с примененным описываемым подходом и результатом его использования:
 |
| Calorie Counter repository |
Список литературы:
Haralick, R.M. and Shapiro, L.G., 1985. Image segmentation techniques. Computer vision, graphics, and image processing, 29(1), pp.100-132.
Lu, D. and Weng, Q., 2007. A survey of image classification methods and techniques for improving classification performance. International journal of Remote sensing, 28(5), pp.823-870.
Borji, A., Cheng, M.M., Jiang, H. and Li, J., 2015. Salient object detection: A benchmark. IEEE transactions on image processing, 24(12), pp.5706-5722.
Qin, X., Zhang, Z., Huang, C., Dehghan, M., Zaiane, O.R. and Jagersand, M., 2020. U2-Net: Going deeper with nested U-structure for salient object detection. Pattern Recognition, 106, p.107404.
Bossard, L., Guillaumin, M. and Van Gool, L., 2014, September. Food-101–mining discriminative components with random forests. In European conference on computer vision (pp. 446-461). Springer, Cham.