
Находясь в поисках темы для ВКР и являясь по совместительству музыкантом пришла мне идея написать приложение, которая будет распознавать рукописные ноты и переводить их в удобный цифровой формат. Сама идея возникла очень просто: какие бы возможности не представлял нотный редактор, написать ноты от руки намного быстрее, однако хранить и передавать в таком виде уже не так удобно. В своих поисках я обнаружила, что эта тема является актуальной последнее десятилетие, однако развита не так хорошо, как распознавание символов в общем. Одним из важных вопросов для написания данной системы являлось наличие датасетов для обучения нейронных сетей. Таким образом, данная статья посвящена обзору существующих датасетов.
Для себя я отметила следующие датасеты, подходящие для разработки такого приложения.
The Handwritten Online Musical Symbols (HOMUS)

Рис 1. Пример данных HOMUS.
Этот набор данных является одним из первых датасетов, созданных для решения поставленной задачи. Он состоит из 15200 образцов 32х музыкальных символов от 100 разных музыкантов. Преимущество данного набора:
Разнообразие “музыкального” почерка, что позволяет с большей вероятностью распознать знак.
Набор создавался с целью интерактивного распознавания нотных знаков, но он так же хорошо справляется с заранее записанными знаками.
CVC-MUSCIMA, MUSCIMA++, MUSCIMA++ Measure Annotations, Baró Single Stave Dataset

Рис 2. Пример данных CVC-MUSCIMA,MUSCIMA++,MUSCIMA++ MA.

Рис 3. Baró Single Stave Dataset
Я объединила эти датасеты в один пункт, так как они являются вариациями друг друга. Изначально была создана база данных СVС-MUSSIMA. Этот датасет был создан с целью обнаружения и удаления нотного стана (линеек) для упрощения последующей классификации и сегментации нотных знаков, и подтверждения авторства за счет анализа “музыкального” почерка. Набор включает в себя 20 нотных листов, которые были переписаны 50-ю разными музыкантами. MUSCIMA++ в свою очередь является расширением СVС-MUSSIMA, а именно этот датасет ориентирован на обучение классификатора нотных знаков. MUSCIMA++ Measure Annotations дополнительно содержит метки для распознавания тактов и самого нотного стана. Baró Single Stave Dataset также является производным от СVС-MUSSIMA.
Capitan collection
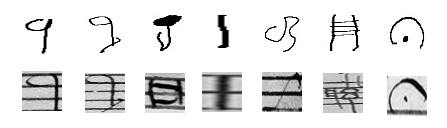
Рис 3. Capitan collection
Этот датасет ориентирован на распознавание ранних(16-18 век) рукописных партитур для автоматизации перевода нот в цифровой формат. Набор состоит из 10230 образцов разбитых на 30 классов. Датасет существует в двух вариантах. Первый вариант аналогичен набору HOMUS. Второй - это визуализированные изображения внутри изолированного набора рукописных музыкальных символов.
Universal Music Symbol Collection

Рис 4. Universal Music Symbol Collection
Этот набор содержит более 90000 символов и на данный момент является самым большим датасетом. По сути он является объединением всех представленных в данной статье датасетов. Он включает в себя как печатные знаки так и рукописные, которые составляют большую часть датасета. Классификаторы обученные на данном наборе обеспечивают высокую точность распознавания. Но несмотря на высокую эффективность обучения на этом наборе, он имеет несколько недостатков:
Содержит только современные обозначения. Однако данный недостаток не является существенным минусом для моей работы.
Набор содержит некоторую часть не распознаваемых символов.
Ноты без штиля недостаточно представлены, так как большинство наборов из которых собирался датасет не содержит таких нот.
Набор несбалансирован. Например, некоторые классы знаков имеют менее 10 образцов, когда как другие - более тысячи. Классификатор, обученный на этом датасете, может начать игнорировать классы с меньшим количеством образцов.
Исходя из обзора, Universal Music Symbol Collection является оптимальным вариантом для разработки приложения распознавания рукописных нот. Но стоит отметить, что классификация является только частью решения поставленной задачи. Также необходимо решить такие проблемы, как предобработка изображения перед распознаванием и “расставление” распознанных музыкальных знаков на нотоносце (нотных линейках).