ОГЛАВЛЕНИЕ
За последние годы
компьютерное зрение набрало популярность и выделилось в отдельное направление.
Разработчики создают новые приложения, которыми пользуются по всему миру.
В этом направлении наиболее
привлекательной выглядит концепция открытого исходного кода. Даже
технологические гиганты готовы делиться новыми открытиями и инновациями со
всеми, чтобы технологии не оставались привилегией богатых. Этим объясняется
актуальность представленной работы.
Одна из таких технологий
— распознавание лиц. При правильном и этичном использовании эта технология
может применяться во многих сферах жизни.
Одной из основных задач компьютерного
зрения является автоматическое обнаружение объекта без вмешательства человека.
Например, определение человеческих лиц на изображении.
Лица людей отличаются друг от друга. Но в
целом можно сказать, что всем им присущи определенные общие черты.
Существует много алгоритмов обнаружения
лиц. Одним из старейших является алгоритм Виолы–Джонса. Он был предложен в 2001
году и применяется по сей день.
Целью настоящей работы является раскрытие
алгоритма аутентификации посещаемости с использованием распознавания лиц.
Для реализации поставленной цели работы
были выдвинуты следующие задачи:
1.
Прояснить
понятие распознавания лиц.
2.
Определение
термина OpenCV.
3.
Как
изольётся Python
в вопросе распознавания лиц.
4.
Как
реализуется представленный алгоритм на готовых изображениях.
Предмет представленной работы —
алгоритмизация аутентификации человеческих лиц.
Объект — использование языка Python для автоматизации
распознавания лиц.
Обнаружение лиц обычно является первым
шагом для решения более сложных задач, таких как распознавание лиц или
верификация пользователя по лицу. Но оно может иметь и другие полезные
применения.
Вероятно, самым успешным использованием
обнаружения лиц является фотосъёмка. В процессе фотографирования, встроенный в
цифровую камеру алгоритм распознавания лиц определяет, где находятся лица людей,
и соответствующим образом регулирует фокус.
Итак, в создании алгоритмов обнаружения
лиц на сегодняшний день человек преуспел. А можно ли также распознавать, чьи
это лица?
Распознавание лиц — это метод идентификации
или подтверждения личности человека по его лицу. Существуют различные алгоритмы
распознавания лиц, но их точность может различаться. В настоящей работе будет
предложено использование распознавания лиц при помощи глубокого обучения.
Для распознавания лица при помощи
глубокого обучения необходимо произвести преобразование, или, иными словами,
эмбеддинг (embedding), изображения лица в числовой вектор. Это также
называется глубоким метрическим обучением.
Указанное действие можно разбить на 3
шага:
1.
Обнаружение
лиц.
2.
Извлечение
признаков.
3.
Сравнение
лиц
Первой задачей является обнаружение лиц
на изображении или в видеопотоке. Далее, когда точно определено местоположение
или координаты лица, необходимо взять это лицо для дальнейшей обработки.
Вырезав лицо из изображения, нужно
извлечь из него характерные черты. Для этого можно использовать процедуру под
названием эмбеддинг.
Нейронная сеть принимает на вход
изображение, а на выходе возвращает числовой вектор, характеризующий основные
признаки данного лица. В машинном обучении такой вектор как раз и называется
эмбеддингом.
Во время обучения нейронная сеть учится
выдавать близкие векторы для лиц, которые выглядят похожими друг на друга.
Например, если есть несколько изображений
лица одного человека в разные моменты времени, то естественно, что некоторые
черты могут меняться, но всё же незначительно. Таким образом, векторы этих
изображений будут очень близки в векторном пространстве. Чтобы получить общее
представление об этом, можно посмотреть на рис. 1.

Рисунок 1 — Подобные изображения лиц
Чтобы определять лица одного и того же
человека, сеть будет учиться выводить векторы, находящиеся рядом в векторном
пространстве. После обучения эти векторы трансформируются следующим образом
(рис. 2):

Рисунок 2 — Подобные изображения лиц после обработки нейронной сетью
В рассматриваемой задаче нет
необходимости заниматься обучением подобной сети. Это требует значительных
вычислительных мощностей и большого объёма размеченных данных. Вместо этого
используется уже предобученная Д. Кингом нейронная сеть. Она обучалась
приблизительно на 3 000 000 изображений. Эта сеть выдаёт вектор
длиной 128 чисел, который и определяет основные черты лица.
После передачи всех изображений в эту
предобученную сеть на выходе получаем соответствующие вектора (эмбеддинги) и
затем сохраним их в файл для следующего шага.
Когда есть вектор (эмбеддинг) для каждого
лица из базы данных, необходимо научиться распознавать лица из новых изображений.
Таким образом, нужно вычислить вектор для нового лица, а затем сравнить его с
уже имеющимися векторами. Можно распознать лицо, если оно похоже на одно из
лиц, уже имеющихся в базе данных. Это означает, что их вектора будут
расположены вблизи друг от друга, как показано на рис. 3.
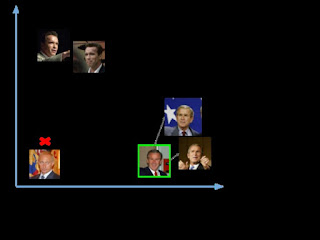
Рисунок 3 — Появление новых лиц в системе
Итак, были переданы в сеть две
фотографии, одна Владимира Путина, другая Джорджа Буша. Для изображений Буша
были вектора (эмбеддинги), а для Путина ничего не было. Таким образом, после сравнения
эмбеддинг нового изображения Буша, он был близок с уже имеющимися векторам, и сеть
его распознала. А вот изображений Путина в базе не было, поэтому распознать его
не удалось.
В области искусственного интеллекта
задачи компьютерного зрения — одни из самых интересных и сложных.
Компьютерное зрение работает как мост между
компьютерным программным обеспечением и визуальной картиной вокруг нас. Оно даёт
ПО возможность понимать и изучать все видимое в окружающей среде.
Например, на основе цвета, размера и
формы плода можно определить разновидность определённого фрукта. Эта задача
может быть очень проста для человеческого разума, однако в контексте
компьютерного зрения всё выглядит иначе.
Сначала нужно собирать данные, затем
выполнить определённые действия по их обработке, а потом многократно обучить
модель, как ей распознавать сорт фрукта по размеру, форме и цвету его плода.
В настоящее время существуют различные
пакеты для выполнения задач машинного обучения, глубокого обучения и
компьютерного зрения. И безусловно, модуль, отвечающий за компьютерное зрение,
проработан лучше других.
OpenCV — это библиотека с открытым
программным кодом. Она поддерживает различные языки программирования, например
R и Python. Работать она может на многих платформах, в частности — на Windows,
Linux и MacOS.
Основные преимущества OpenCV:
- имеет
открытый программный код и абсолютно бесплатна
- написана
на C/C++ и в сравнении с другими библиотеками работает быстрее
- не
требует много памяти и хорошо работает при небольшом объёме RAM
- поддерживает
большинство операционных систем, в том числе Windows, Linux и MacOS.
Далее будет рассматриваться установку
OpenCV только для языка Python.
Установить её при помощи менеджеров pip или conda (в случае, если у
установлен пакет Anaconda).
1.
При помощи pip
При помощи pip процесс установки может
быть выполнен с использованием следующей команды:
pip
install opencv-python
2.
Anaconda
При использовании Anaconda необходимо выполнить
следующую команду в окружении Anaconda:
conda
install -c conda-forge opencv
3
Распознавание лиц с использованием Python
Предлагается рассмотреть, какие
библиотеки потребуются и как их установить:
- OpenCV
- dlib
- Face_recognition
OpenCV
— это библиотека обработки изображений и видео, которая используется для их
анализа. Её применяют для обнаружения лиц, считывания номерных знаков,
редактирования фотографий, расширенного роботизированного зрения, оптического
распознавания символов и многого другого.
Библиотека dlib, поддерживая Дэвисом Кингом, содержит
реализацию глубокого метрического обучения. Она будет использоваться для
конструирования векторов (эмбеддингов) изображений, играющих ключевую роль в
процессе распознавания лиц.
Библиотека face_recognition, созданная Адамом Гейтгеем, включает в себя функции распознавания
лиц dlib
и является по сути надстройкой над ней. С ней очень легко
работать, и она будет использоваться далее.
Для установки OpenCV необходимо в
командной строке прописать:
pip
install opencv-python
Простейшим способом установки библиотеки
для Windows
является Anaconda. Поэтому для начала нужно установить Anaconda,
после чего ввести в терминале следующую команду:
conda
install -c conda-forge dlib
Далее, для установки библиотеки face recognition необходимо прописать следующее:
pip
install face_recognition
Теперь, когда все необходимые модули
установлены, можно начинать писать код. Необходимо будет создать три файла.
Первый файл будет принимать датасет с
изображениями и выдавать эмбеддинг для каждого лица. Эти эмбеддинги будут
записываться во второй файл. В третьем файле будем сравнивать лица с уже
существующими изображениями. А затем сделаем тоже самое в стриме с веб–камеры.
Для начала необходимо достать датасет с
лицами или создать свой собственный. Главное, чтобы все изображения находились
в папках, причём в каждой папке должны быть фотографии одного и того же
человека.
Затем нужно разместить датасет в рабочей
директории, то есть там, где будет создаваться собственные файлы.
Сам код представлен в приложении 1.
Сейчас были сохранены все эмбеддинги в
файл под названием face_enc.
Теперь можно их использовать для распознавания лиц на изображениях или во время
видеострима с веб–камеры.
Код для распознавания лиц из прямой
трансляции веб–камеры представлен в приложении 2.
В приведённом примере для обнаружения лиц
использовался метод cv2.CascadeClassifier() из библиотеки OpenCV. Но вы с таким же успехом можете
пользоваться и методом face_recognition.face_locations(), как мы уже делали в
предыдущем примере.
4
Распознавание лиц на изображениях
Код для обнаружения и распознавания лиц
на изображениях почти аналогичен тому, что был приведён в приложении 3.
Результат:


Рисунок 5 — Фотография молодого человека с распознанным лицом
СПИСОК
ИСПОЛЬЗОВАННОЙ ЛИТЕРАТУРЫ
2. Распознавание лиц при помощи Python и OpenCV // Pythonist | образовательная платформа по Python [Электронный ресурс]. URL: https://pythonist.ru/raspoznavanie-licz-pri-pomoshhi-python-i-opencv/ (режим доступа: 01.10.2021)
3. Создание модели распознавания лиц с использованием глубокого обучения на языке Python / Блог компании Нетология / Хабр // Все публикации подряд / Хабр [Электронный ресурс]. URL: https://habr.com/ru/company/netologyru/blog/434354/ (режим доступа: 01.10.2021)
from imutils import paths
import face_recognition
import pickle
import cv2
import os
# в директории Images
хранятся папки со всеми изображениями
imagePaths =
list(paths.list_images('Images'))
knownEncodings = []
knownNames = []
# перебираем все папки с изображениями
for (i, imagePath) in
enumerate(imagePaths):
# извлекаем имя человека из названия папки
name = imagePath.split(os.path.sep)[-2]
# загружаем изображение и конвертируем его из BGR (OpenCV ordering)
# в dlib ordering (RGB)
image = cv2.imread(imagePath)
rgb = cv2.cvtColor(image,
cv2.COLOR_BGR2RGB)
#используем библиотеку Face_recognition для обнаружения лиц
boxes =
face_recognition.face_locations(rgb,model='hog')
# вычисляем эмбеддинги для каждого лица
encodings =
face_recognition.face_encodings(rgb, boxes)
# loop over the encodings
for encoding in encodings:
knownEncodings.append(encoding)
knownNames.append(name)
# сохраним эмбеддинги вместе с их именами в формате
словаря
data = {"encodings":
knownEncodings, "names": knownNames}
# для сохранения данных в файл используем метод pickle
f = open("face_enc",
"wb")
f.write(pickle.dumps(data))
f.close()
import face_recognition
import imutils
import pickle
import time
import cv2
import os
# find path of xml file containing
haarcascade file
cascPathface = os.path.dirname(
cv2.__file__) +
"/data/haarcascade_frontalface_alt2.xml"
# load the harcaascade in the cascade
classifier
faceCascade =
cv2.CascadeClassifier(cascPathface)
# load the known faces and embeddings saved
in last file
data = pickle.loads(open('face_enc',
"rb").read())
print("Streaming started")
video_capture = cv2.VideoCapture(0)
# loop over frames from the video file
stream
while True:
# grab the frame from the threaded video
stream
ret, frame = video_capture.read()
gray = cv2.cvtColor(frame,
cv2.COLOR_BGR2GRAY)
faces = faceCascade.detectMultiScale(gray,
scaleFactor=1.1,
minNeighbors=5,
minSize=(60, 60),
flags=cv2.CASCADE_SCALE_IMAGE)
# convert the input frame from BGR to RGB
rgb = cv2.cvtColor(frame,
cv2.COLOR_BGR2RGB)
# the facial embeddings for face in input
encodings =
face_recognition.face_encodings(rgb)
names = []
# loop over the facial embeddings incase
# we have multiple embeddings for multiple
fcaes
for encoding in encodings:
# Compare encodings with encodings in
data["encodings"]
# Matches contain array with boolean values
and True for the embeddings it matches closely
# and False for rest
matches =
face_recognition.compare_faces(data["encodings"],
encoding)
# set name =inknown if no encoding matches
name = "Unknown"
# check to see if we have found a match
if True in matches:
#Find positions at which we get True and
store them
matchedIdxs = [i for (i, b) in
enumerate(matches) if b]
counts = {}
# loop over the matched indexes and
maintain a count for
# each recognized face face
for i in matchedIdxs:
# Check the names at respective indexes we
stored in matchedIdxs
name = data["names"][i]
# increase count for the name we got
counts[name] = counts.get(name, 0) + 1
# set name which has highest count
name = max(counts, key=counts.get)
# update the list of names
names.append(name)
# loop over the recognized faces
for ((x, y, w, h), name) in zip(faces,
names):
# rescale the face coordinates
# draw the predicted face name on the image
cv2.rectangle(frame, (x, y), (x + w, y +
h), (0, 255, 0), 2)
cv2.putText(frame, name, (x, y),
cv2.FONT_HERSHEY_SIMPLEX,
0.75, (0, 255, 0), 2)
cv2.imshow("Frame", frame)
if cv2.waitKey(1) & 0xFF ==
ord('q'):
break
video_capture.release()
cv2.destroyAllWindows()
import face_recognition
import imutils
import pickle
import time
import cv2
import os
# find path of xml file containing
haarcascade file
cascPathface = os.path.dirname(
cv2.__file__) + "/data/haarcascade_frontalface_alt2.xml"
# load the harcaascade in the cascade
classifier
faceCascade =
cv2.CascadeClassifier(cascPathface)
# load the known faces and embeddings saved
in last file
data = pickle.loads(open('face_enc',
"rb").read())
# Find path to the image you want to detect
face and pass it here
image = cv2.imread(Path-to-img)
rgb = cv2.cvtColor(image,
cv2.COLOR_BGR2RGB)
# convert image to Greyscale for
haarcascade
gray = cv2.cvtColor(image,
cv2.COLOR_BGR2GRAY)
faces = faceCascade.detectMultiScale(gray,
scaleFactor=1.1,
minNeighbors=5,
minSize=(60, 60),
flags=cv2.CASCADE_SCALE_IMAGE)
# the facial embeddings for face in input
encodings =
face_recognition.face_encodings(rgb)
names = []
# loop over the facial embeddings incase
# we have multiple embeddings for multiple
fcaes
for encoding in encodings:
# Compare encodings with encodings in
data["encodings"]
# Matches contain array with boolean values
and True for the embeddings it matches closely
# and False for rest
matches = face_recognition.compare_faces(data["encodings"],
encoding)
# set name =inknown if no encoding matches
name = "Unknown"
# check to see if we have found a match
if True in matches:
# Find positions at which we get True and
store them
matchedIdxs = [i for (i, b) in enumerate(matches)
if b]
counts = {}
# loop over the matched indexes and
maintain a count for
# each recognized face face
for i in matchedIdxs:
# Check the names at respective indexes we
stored in matchedIdxs
name = data["names"][i]
# increase count for the name we got
counts[name] = counts.get(name, 0) + 1
# set name which has highest count
name = max(counts, key=counts.get)
# update the list of names
names.append(name)
# loop over the recognized faces
for ((x, y, w, h), name) in zip(faces,
names):
# rescale the face coordinates
# draw the predicted face name on the image
cv2.rectangle(image, (x, y), (x + w, y +
h), (0, 255, 0), 2)
cv2.putText(image, name, (x, y),
cv2.FONT_HERSHEY_SIMPLEX,
0.75, (0, 255, 0), 2)
cv2.imshow("Frame", image)
cv2.waitKey(0)